
역할 | DevOps & Infra Leader |
프로젝트 기간 | 2023.12 ~ 2024.02 |
참여 인원 | 10 명 (FE 4, BE 4, Infra 2) |
목차
소개
본 프로젝트인 'DPANG'은 자사 쇼핑몰 웹사이트 구축을 목표로 한, 특수한 특성을 가진 폐쇄형 쇼핑몰입니다. DPANG 쇼핑몰은 회사 구성원만이 회원으로 가입하고 접근할 수 있으며, 연간 100만 마일리지를 통해 시중의 상품을 할인된 가격으로 구매할 수 있는 시스템을 제공합니다.
‘DPANG’ 프로젝트에서 저는 인프라 직무의 팀장을 맡아 프로젝트를 기획하고 구현하는 과정을 가졌습니다. 인프라 직무로서 작업한 업무들과 사용 환경은 다음과 같습니다:
•
시스템 아키텍처 구축 (Figma)
•
클라우드 환경 서버/네트워크/데이터베이스 구축 (Kakao Cloud, MySQL, Redis)
•
서비스 컨테이너화 (Docker)
•
컨테이너 오케스트레이션 (Kubernetes)
•
CI/CD (Git Actions, ArgoCD)
•
모니터링 (Grafana, Prometheus, Loki)
•
데이터 분석 및 시각화 (ElasticSearch, Logstash, Kibana)
1) 시스템 구성도
전체적인 시스템의 구조와 흐름을 파악할 수 있도록 시스템 구성도를 설계하였습니다. 해당 시스템 구성도에는 클라우드의 네트워크와 각 서비스 간의 연동 구조, 데이터베이스, CI/CD, MSA 서버 구조 등이 포함되어 있습니다.
1.1) 초기 시스템 구성도
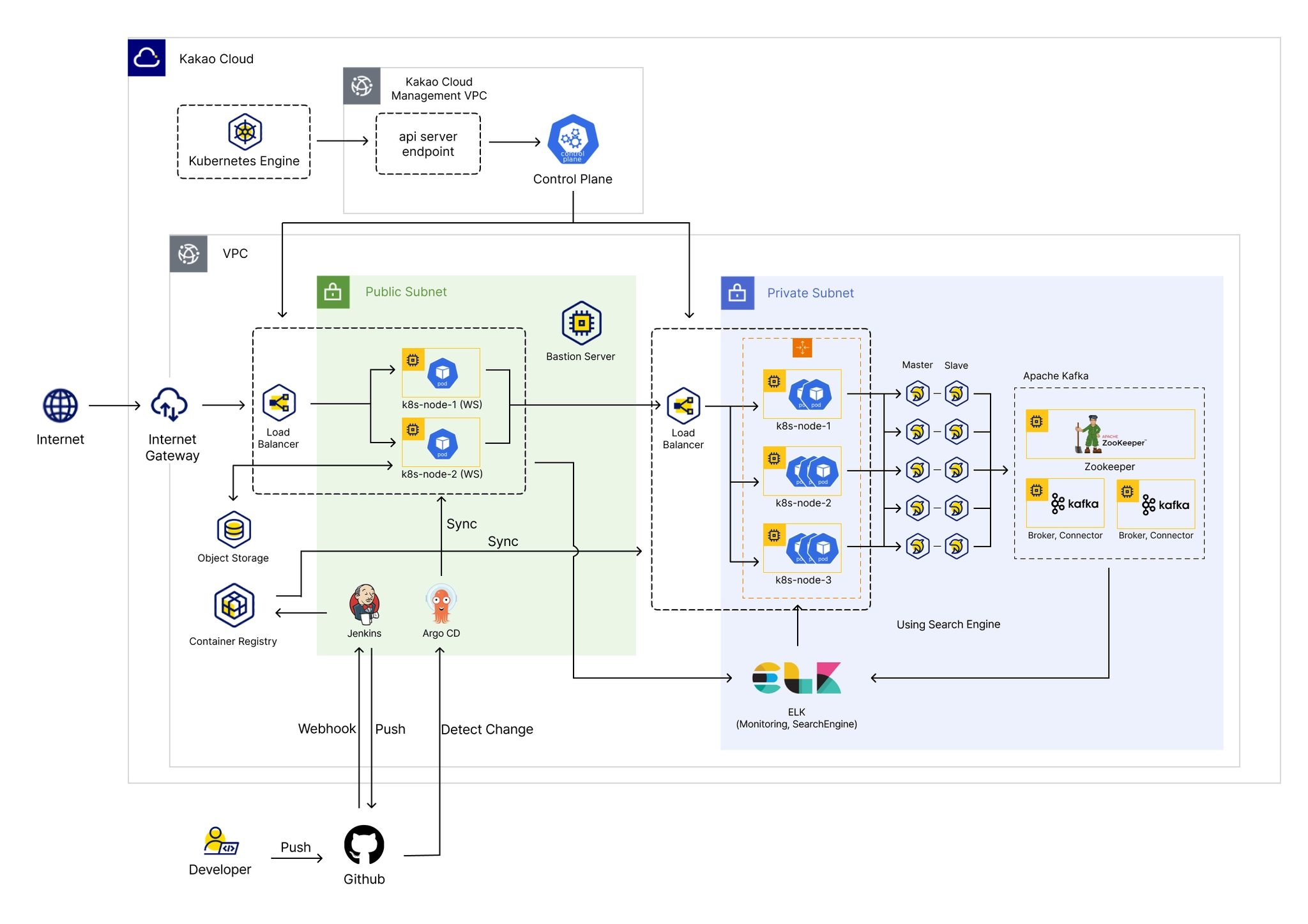
•
네트워크 구성
하나의 VPC에 Public Subnet과 Private Subnet을 설정하여 웹 서버는 인터넷 게이트웨이를 통한 외부 통신이 가능하도록 하고, 데이터베이스와 웹 애플리케이션 서버는 Private Subnet에 두어 외부 접근을 차단했습니다.
•
웹 서버
웹 서버는 쿠버네티스 노드 풀로 그룹화된 인스턴스에 웹 서버에 대한 파드를 생성하여 이중화됩니다. 로드밸런서를 통한 부하 분산과 이중화를 통해 고가용성과 고성능을 보장하도록 했습니다. 웹 서버는 쇼핑몰에서 사용되는 이미지 파일들을 저장하기 위해 Kakao Cloud의 서비스인 Object Storage 서비스와 연결시켰습니다.
•
웹 애플리케이션 서버
WAS는 MSA로 구성되어 각 서비스를 독립적으로 실행시키도록 컨테이너화하였습니다. 각 서비스는 Auth, User, Item, Order, Mileage, FAQ, Notification, QnA, Seller, Event을 포함합니다.
Private Subnet에서의 노드와 파드를 유지하기 위해 WAS에 해당하는 서비스들은 특정 노드에만 스케줄링이 되도록 설정하고, 트래픽 증가에 대응하기 위해 HPA와 노드 오토 스케일링을 통하여 부하를 분산하여 해결토록 계획했습니다.
•
데이터베이스
데이터베이스는 Kakao Cloud의 MySQL 서비스를 사용하며, 상품들에 대한 분석과 검색엔진으로 사용하기 위해 ElasticSearch 사용을 계획했습니다. MySQL은 Primary, Second DB를 두어 Active-Stanby로 구성하여 데이터베이스의 안정성을 지키도록 했습니다.
Kafka를 사용하여 Elasticsearch와 MySQL 간에 CDC 과정을 가지고, 이를 통해 데이터 시각화와 검색 기능을 구현하고자 했습니다.
데이터베이스를 RDBMS인 MySQL로 선택한 이유는 다음과 같습니다:
◦
표준 SQL 지원
◦
트랜잭션 지원: 데이터의 무결성 보장
◦
관계형 데이터 모델링: 데이터 간 관계 표현, 데이터 중복 최소화, 데이터 무결성 보장
•
배포 전략
무중단 배포를 위해 쿠버네티스를 도입하고, CI/CD 전략으로 GitOps를 사용함에 따라 다양한 SCM과의 연결을 지원하는 Jenkins와 쿠버네티스의 자동화 배포를 지원하는 ArgoCD를 사용할 것을 계획했습니다. Github에 커밋 및 푸시가 이루어지면 Jenkins를 통해 이미지를 빌드하고, Container Registry에 업로드합니다. 그 후, ArgoCD를 통해 쿠버네티스에 이미지를 동기화시켜 자동 배포를 이루도록 하였습니다.
1.2) 최종 시스템 구성도
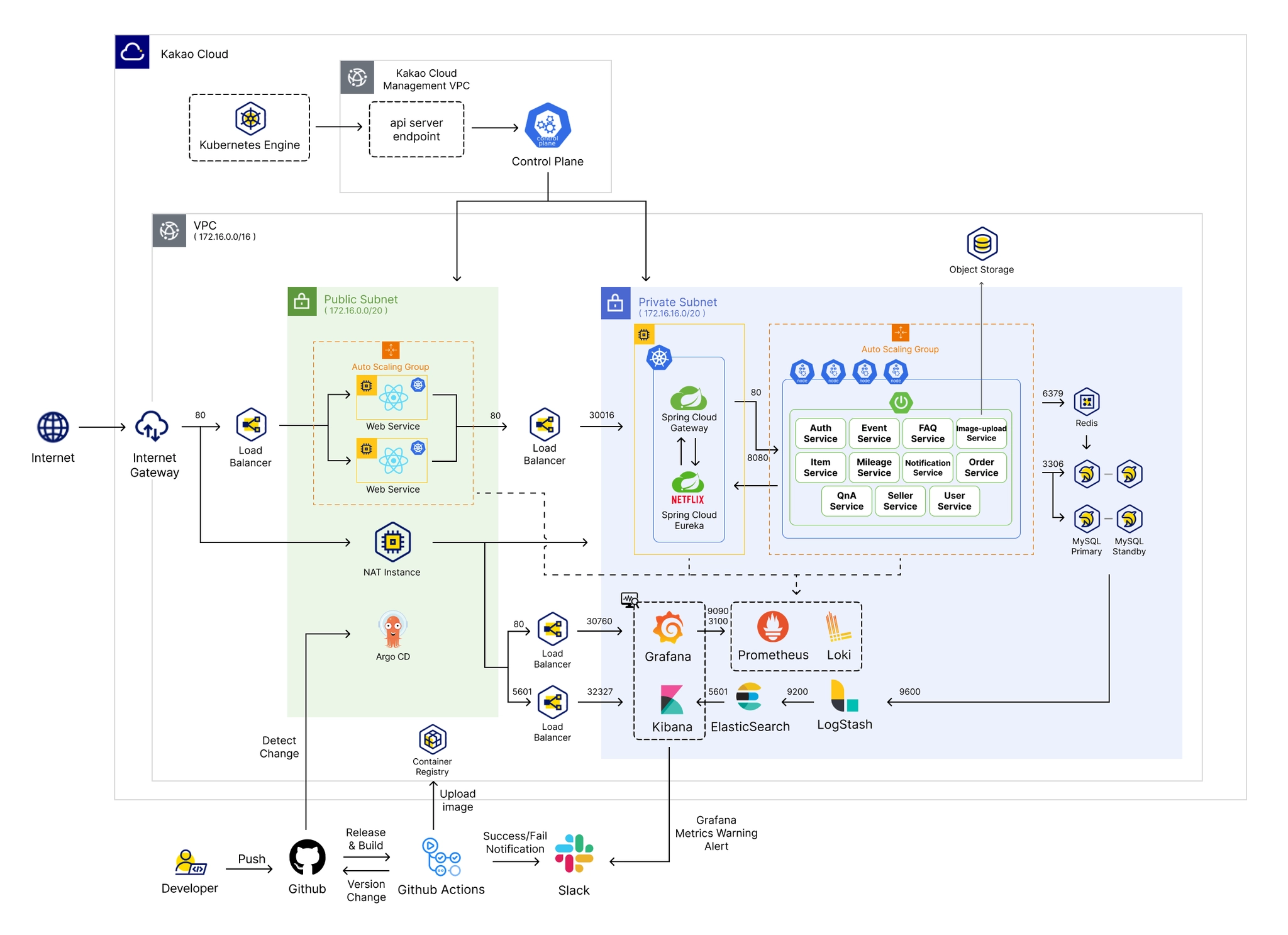
기존에 기획 단계에서 작성하였던 초기 아키텍처와의 변경점은 네트워크, CI/CD 운영 전략, 서비스의 인증 및 인가, 캐싱 메모리, 모니터링, 데이터 파이프라인의 변화입니다.
•
네트워크 구성
인터넷 연결을 허용하지 않는 Private Subnet에서의 패키지 및 라이브러리 설치와 같은 인터넷 사용을 위해 NAT Instance를 두었습니다.
•
운영 전략
CI 과정을 Jenkins에서 Github Actions로 변경하였으며, 이로 인해 서버 필요성 해소와 Github와의 통합을 강화하였습니다.
Jenkins를 사용하기 위해서는 별도의 서버가 필요하지만 Github Actions는 Github 클라우드 기반에서 실행되기 때문에 서버 필요성이 해소되어 추가적인 서버 리소스 사용과 비용을 절감할 수 있었습니다.
Github Actions는 현재 프로젝트 과정에서 SCM으로 사용하는 Github와의 통합이 자연스러우며, 젠킨스보다 더 간단하고 빠른 설정이 가능하기 때문에 Github와의 통합 강화로서 운영 전략을 바꾸게 되었습니다.
•
서비스의 인증 및 인가
서비스의 인증 및 인가를 위해 쿠버네티스의 ingress oauth와 Spring Cloud Gateway 사용 중 Spring Cloud Gateway를 택하여 각 서비스에 대한 인증 및 인가를 진행하고 라우팅을 진행하는 것으로 구축했습니다. MSA로 구성되어 각각의 서비스가 독립적이며, 사용 언어도 다른 경우가 있지만 사용 프레임워크는 Spring boot로 같습니다. 이 때문에 프레임워크 친화적인 Spring Cloud Gateway를 선택하였습니다. 또한 MSA에서의 확장성과 유연성으로 인해 Spring Cloud Gateway를 인증 및 인가 솔루션으로 사용했습니다.
•
캐싱 메모리
캐싱 메모리로 Redis를 채택하여 적용했습니다. Redis를 통한 빠른 읽기 및 쓰기를 제공함으로써 고성능과 고가용성을 보장하여 서비스의 응답 시간을 단축시키도록 했습니다. 인증과 상품에 대한 데이터를 캐시에 저장함으로써 데이터베이스의 부하를 줄이고 서비스의 성능을 향상시켰습니다.
•
모니터링
필요되는 기능 별로 모니터링 툴을 선정해 Grafana, ElasticSearch로 모니터링을 구축했습니다.
서버의 메트릭 정보는 Prometheus, 로그 정보는 Promtail, Loki를 사용하고 그에 대한 시각화를 Grafana를 통해 진행했습니다. 또한 Grafana를 사용하며 알람 기능을 활용해 Slack으로 특이사항에 대한 알림을 받을 수 있으며, Kakao Cloud의 Kubernetes Engine에 Prometheus로 metrics 정보를 전달하는 exporter가 사전에 구성되어 있어 Grafana를 모니터링 툴로 선택하게 되었습니다.
데이터 분석과 시각화는 ELK Stack을 사용하였습니다. ELK Stack은 사용중인 MySQL의 데이터를 Logstash를 통해 ElasticSearch에 적재하고 그에 대한 분석과 시각화를 Kibana로 진행하였습니다.
•
데이터 파이프라인
초기 아키텍처에서는 데이터 파이프라인 솔루션으로 Kafka를 사용하기로 기획했습니다. 하지만 구현 단계에서 ELK Stack의 Logstash를 사용함으로써 서버 필요성을 해소하고, Elasticsearch와의 친화성을 강화했습니다.
별도의 클러스터 관리가 필요한 Kafka와 달리 리소스가 상대적으로 작은 Logstash를 사용했습니다. 또한 Logstash는 ELK Stack으로, Elasticsearch와 친화적이기 때문에 데이터 적재 및 인덱싱이 Kafka보다 간편하기 때문에 데이터 분석에 필요한 파이프라인으로 Logstash를 선택했습니다.
이 외에 데이터베이스의 크기를 줄였는데, 프로젝트 기간동안 한정된 예산에서의 시스템을 구축해야했고 실제로 비용이 강조되는 클라우드에서 서비스의 크기가 크지 않은 현재의 프로젝트에서 각각의 데이터베이스를 가지는 것은 불필요하다 판단되어 데이터베이스의 수를 줄이게 되었습니다.
2) 데이터베이스
2.1) RDBMS
프로젝트에 적재될 데이터는 쇼핑몰의 특성상 상품, 사용자, 구매, 판매 등 관계적으로 얽혀있어 RDBMS를 사용할 것으로 판단하였습니다. 그에 더해 RDBMS 중 MySQL을 택하여 프로젝트가 진행되었는데 MySQL은 표준 SQL을 지원하고, 데이터 간 관계 표현, 데이터의 무결성 보장에서의 특징이 있고, 팀원들이 가장 많이 사용했던 데이터베이스로 짧은 프로젝트 구현 특성상 가장 사용이 편한 MySQL을 데이터베이스로 사용하였습니다. 또한 Kakao Cloud에서는 MySQL 서비스를 자체적으로 지원하고 있어 사용 가능한 데이터베이스 중 안정성 측면에서 가장 뛰어났기 때문에 사용했습니다.
2.2) Cache
캐싱 메모리로 Redis를 사용했는데, 인증과 상품에 대한 데이터를 캐시로 저장하는 용도로 사용되었습니다. 인증과 상품 데이터에 대한 조회가 자주 일어날 것을 예상해 데이터베이스의 부하가 클 인증과 상품에 대하여 캐싱 메모리로 Redis를 도입하게 되었습니다.
2.3) NoSQL
NoSQL로는 ElasticSearch를 사용했는데, ElasticSearch는 기본적인 CRUD 작업에 사용하지 않았습니다. ElasticSearch는 ELK Stack으로써의 데이터 파이프라인을 구축하고, 프로젝트의 데이터베이스인 MySQL의 데이터를 가져와 인덱싱함으로써 시각화 및 분석을 하기 위해 사용했습니다.
3) MicroService Architecture
저희는 이번 프로젝트를 마이크로서비스 아키텍처로 설계하였습니다. 저희 팀이 MSA를 경험한 이유는 다음과 같습니다:
1.
독립적인 서비스 구성 - 각 서비스가 독립적으로 구성되어 있어 서로 다른 개발 언어를 사용할 수 있으므로 개발 효율성을 높이고, 팀원들이 각자 하나의 서비스를 맡아 개발을 진행할 수 있었습니다.
2.
서비스의 확장성 - MSA는 필요한 서비스만을 독립적으로 확장할 수 있어 시스템의 확장성을 높이고, 리소스 관리를 효율적으로 할 수 있음을 장점으로 가져 개발을 진행했습니다.
3.
장애 격리 - 한 서비스에 문제가 발생했을 때, 독립적인 서비스 구성으로 인해 시스템의 안정성을 높이고, 장애에 대한 대응이 시스템 다운 없이 가능하다는 것을 보고 MSA 구조로 진행했습니다.
4.
배포와 유지보수의 용이성 - 독립적인 운영으로 인해 개발 및 운영 효율성이 높아 MSA를 경험하기로 결정했습니다.
위와 같은 이유들로 MSA에 도전했습니다. 물론 MSA를 구성하며 서로 간에 연동에 대해 많은 문제를 겪고, 진행하며 MSA의 장점들에 대해 의심하기도 했지만 실제로 하나의 서비스에 장애가 발생했을 때 다른 서비스들에 대해서는 문제없이 구동되는 것을 보고 MSA의 장점을 몸소 느낄 수 있었습니다.
4) 쿠버네티스
4.1) Container Ochestration
서비스를 MSA로 구현함에 따라 컨테이너 관리를 위해 쿠버네티스를 고민하게 되었고, 컨테이너 관리의 용이함과 서비스 확장성을 위해 쿠버네티스를 사용하게 되었습니다. 쿠버네티스는 Kakao Cloud에서 제공되는 Kubernetes Engine 서비스를 사용했습니다. 쿠버네티스를 사용함으로써 무중단 배포와 특정 서비스에 대한 확장을 이룰 수 있었습니다.
4.2) GitOps
쿠버네티스에서의 CI/CD 전략으로 Github - Github Actions - ArgoCD의 과정을 갖는 GitOps를 채택했습니다. 현재 프로젝트 과정에서 SCM으로 Github를 사용하기 때문에 Github Actions를 통해 컨테이너의 이미지 빌드 및 업로드가 간편했고, 이에 따라 K8s의 자동화 배포 도구인 ArgoCD를 사용하여 쿠버네티스로의 지속적 배포를 갖췄습니다. 해당 GitOps의 흐름은 다음과 같습니다:
1.
릴리즈 시 Github Actions가 실행되도록 workflow 작성
2.
Github Repository에서 태그 생성 및 릴리즈
3.
Github Actions 실행
4.
이미지 빌드 및 업로드 후 k8s 매니페스트 파일을 관리하는 github 저장소에 이미지 버전 푸시
5.
ArgoCD에서 Github에서의 이미지 변경 감지
6.
동기화 및 배포
4.3) Helm
저희는 이번 프로젝트를 진행하며 저희가 구축한 서비스 이외에 애플리케이션들에 대해서는 Helm Chart를 적극 활용했습니다. Helm을 사용함에 있어 버전 관리 및 추적이 쉬웠고, Helm Chart의 values.yaml을 수정함으로써 현재 구축되어있는 저희 환경에 맞춰 설정할 수 있어 Helm을 도입했습니다.
4.4) 워크로드 관리
구축 초반에는 ArgoCD를 통해 쿠버네티스의 워크로드를 관리하고, Grafana로 메트릭과 로그를 모니터링하여 쿠버네티스 대시보드의 필요성을 느끼지 못했습니다. 하지만 점점 Helm의 사용이 많아지며 Github에서는 관리되지 않는 서비스들은 ArgoCD로 상태확인이 되지 않았고, Grafana로는 상태 확인에 대한 시각적 인지는 바로 되지 않기 때문에 Workload 관리를 위해 쿠버네티스 대시보드를 구축하여 확인했습니다. 대시보드를 구축함으로 인해 ArgoCD에서는 확인되지 않는 서비스들에 대한 시각적인 상태 확인이 즉각적으로 이루어져 장애 대처를 더욱 빠르게 만들 수 있었습니다.
4.5) 스케줄링
저희 프로젝트에서의 네트워크 구성은 Public과 Private 서브넷으로 나눠져있는데 각각 보안적인 부분으로 인해 컨테이너가 실행되는 특정 파드들은 해당 서브넷에 위치한 노드로만 스케줄링이 이뤄져야합니다. 이를 해결하기 위해서 각각의 노드 풀에 노드 레이블을 설정하고, 쿠버네티스 매니페스트 파일에서는 nodeAffinity를 설정함으로써 파드가 스케줄링되는 노드가 일관되도록 설정해주었습니다.
4.6) resources 설정
쿠버네티스 yaml 파일을 작성하며 가장 생각이 많았던 부분이었습니다. 서비스를 실행시켜보기 전에는 해당 서비스가 얼마만큼의 CPU와 메모리를 사용하는지 파악할 수 없었기 때문에 resources.request를 쉽게 설정할 수 없었습니다. 따라서 Grafana + Prometheus를 통해 지속적으로 파드들에 대해 CPU와 메모리 사용량을 모니터링하고 추적하여 request를 설정할 수 있었습니다.
resources.request는 트래픽 분산으로 사용한 HPA와 늘어난 파드에 대한 스케줄링으로 스케일링될 노드 때문에 설정이 요구되었습니다. 이전 프로젝트에서 request를 설정하지 않고 부하 테스트를 진행했을 때 노드의 CPU 총량이 계속해서 늘어났지만 스케줄링이 되지 않는 일이 발생했었기 때문에 이 경험을 바탕으로 request 값을 설정하여 CPU와 Memory에 대한 필수 요구 수치를 설정함으로써 오토 스케일링이 되지 않는 장애를 해결할 수 있었습니다.
5) 모니터링
5.1) Grafana
메트릭과 로그 모니터링이 진행되었는데 두 모니터링은 쿠버네티스 상에서 실행되는 서비스들에 대한 정보들에 대한 모니터링이었습니다. 저희는 쿠버네티스를 사용하긴 했지만 Swagger UI 확인을 위해서 공용 IP(Public IP)를 가진 하나의 VM에 도커 환경으로 개발 환경을 구축했었습니다. Swagger UI 확인이 쿠버네티스에서 확인할 수 없었던 것은 쿠버네티스는 외부에서의 접근을 위해서는 k8s 서비스 타입을 LoadBalancer로 두어야했습니다. MSA로 구축하여 10개 이상의 서비스를 가지는데 공용 IP를 부여한 LB를 그만큼 가질 수 없었고, 이에 대한 대응으로 ingress 사용이 있었지만 path 지정으로 인해 작업되어있던 백엔드 코드들을 수정하는 방법보다 도커를 사용하는 방법을 채택해 ingress 사용을 하지 않았습니다.
따라서 로그 모니터링이 도커와 쿠버네티스 환경 두 곳에서 이뤄져야 했고, 이를 위해 도커 환경에서는 Loki, Promtail 만을 구축하여 쿠버네티스에 구축된 Grafana에서 시각화를 이뤘습니다.
5.2) ELK Stack
데이터 분석과 시각화를 위해 ELK Stack을 사용했습니다. 데이터 파이프라인으로는 Logstash를 사용했는데 모든 데이터를 인덱싱하는 것보다 대시보드로 만들었을 때 의미 있게 사용가능한 데이터를 분류하고 적재하기 위해 팀원과 논의를 거쳐 ElasticSearch에 적재할 데이터를 선별했습니다.
Logstash를 사용하며 데이터 중복을 피하기 위해 같은 식별자를 가지는 데이터에 한하여 overwrite하는 방식을 가졌는데 시계열 값도 변경되어 누적 데이터가 쌓이지 않고 갱신이 되는 문제가 발생했습니다. 이를 위해 ‘재고량의 변화 추이’ 같은 시계열 데이터에 따라 값의 변화를 추적해야 하는 데이터를 분석하고 이러한 데이터는 데이터 중복이 발생할 수 있도록 파이프라인을 설정했습니다.
결론
이번 프로젝트에서 인프라 직무를 경험하며 복잡한 시스템을 설계하고 구현하는 능력을 키울 수 있었고, 기술적인 이해도와 문제 해결 능력, 팀워크 역량을 향상시킬 수 있었습니다.
먼저, 다양한 데이터베이스와 MSA, 쿠버네티스, 프론트엔드/백엔드의 작업 플로우를 배우고, 기술을 실제 프로젝트에 적용하면서 해당 기술들의 장단점 및 특징들에 대해 확인할 수 있었습니다. 이로 인해 기술적인 이해도를 넓힐 수 있었고, 해당 기술들에 대한 구현 능력을 키울 수 있었습니다.
둘째로, 장애가 발생했을 때 대응하는 방식과 능력을 향상시킬 수 있었습니다. 특히 쿠버네티스를 모니터링하며 발생하는 이슈들을 해결하면서, 원인을 찾아내고 그에 맞는 해결책을 찾아내는 능력을 키울 수 있었습니다. 특히 MSA 구조로 이뤄진 서비스에서 잦은 연동 장애로 인해 모니터링의 중요성을 확인할 수 있었습니다. 이를 통해 앞으로 다양한 문제 상황에서 대처할 수 있는 능력을 갖추는데 도움이 되었습니다.
마지막으로, 팀 프로젝트를 통해 팀원들과의 협력과 의사소통의 중요성을 깨닫게 되었습니다. 인프라 및 데브옵스 파트를 맡으며 프론트엔드와 백엔드 모두와 긴밀한 의사소통을 가질 수 있었습니다. 또한 MSA로 인해 계속된 소통이 이뤄졌고, 이를 통해 작업 흐름을 파악하고 진행 및 완료된 경험이 팀워크의 중요성을 깨닫게 해주었습니다.
이번 프로젝트를 통해 다양한 기술들과 문제 해결, 팀워크를 경험하며 앞으로의 경력에서도 발전할 수 있기를 기대합니다.