목차
1. 개요
•
프로젝트명: COME2US
•
목표:
◦
단일 MVP(Sprint #1)에서 MSA로 확장
◦
자동화된 배포 및 IaC 기반 운영
◦
Jenkins CI/CD 파이프라인 구축
◦
ECS 기반 컨테이너 서비스 운영
◦
Multi-AZ 기반 고가용성 및 Blue/Green 무중단 배포 실현
•
핵심 구성 계층
계층 | 주요 구성 요소 |
Network Layer | VPC, Subnet, NAT Gateway, ALB, Route53 |
Application Layer | ECS(Fargate), Spring Cloud (Gateway / Eureka / Config Server) |
Data Layer | RDS(PostgreSQL), ElastiCache(Redis Session/Cache), MSK(Kafka), S3 |
DevOps Layer | Jenkins, ECR, Terraform, Packer |
Observability Layer | CloudWatch (Logs / Metrics / Alarms), Discord Notification |
2. 시스템 아키텍처 요약
아키텍처 다이어그램
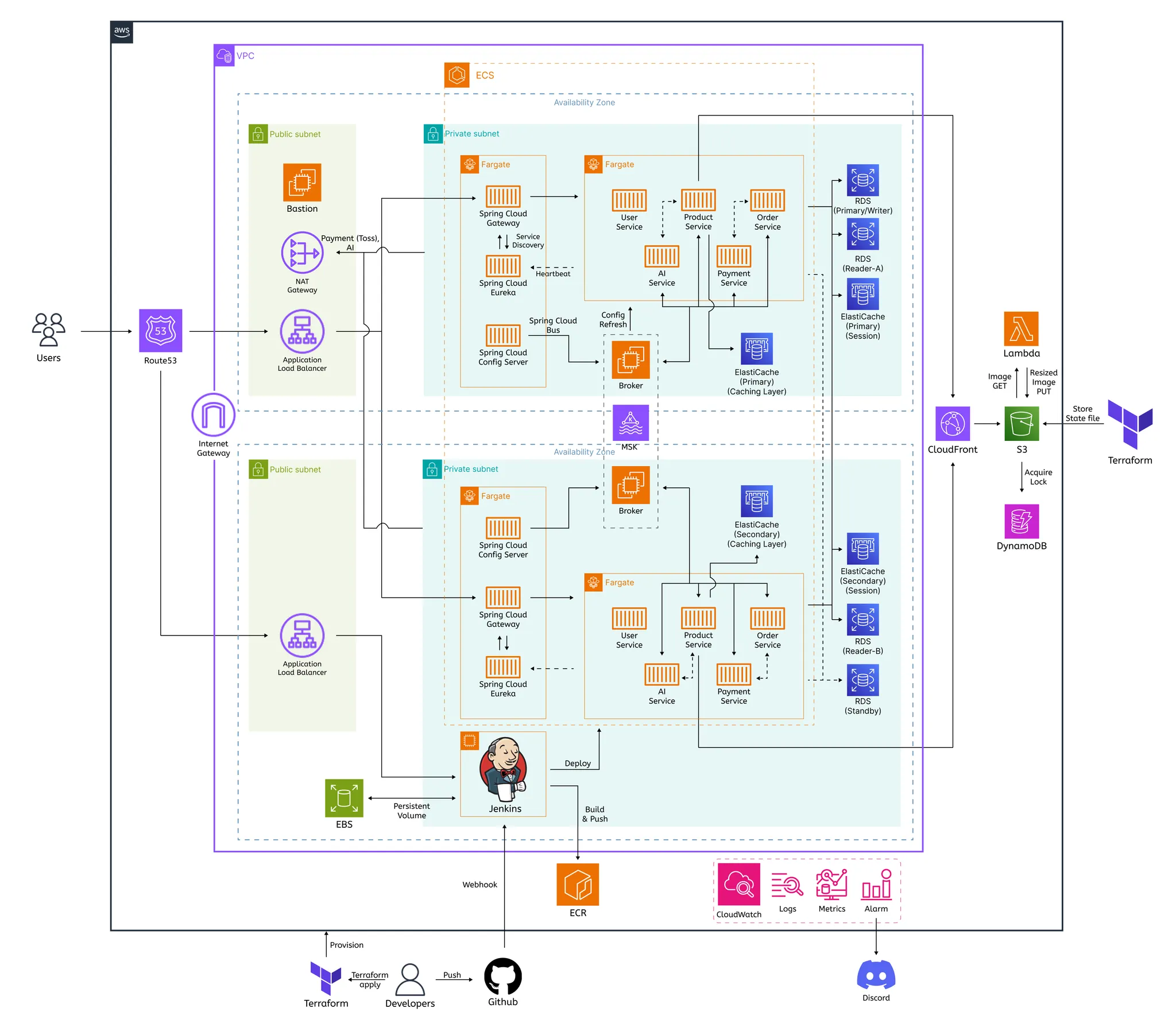
•
MSA 구성 서비스
◦
User Service (Auth, Member)
◦
Product Service (Product, Review, Store, Category, DeliveryPolicy, Cart)
◦
Order Service (Order, Coupon, Refund, DeliveryAddress)
◦
Payment Service
◦
AI Service
•
운영 구조
◦
ECS(Fargate) 기반 컨테이너 서비스
◦
Spring Cloud Gateway, Eureka, Config Server 포함
◦
Jenkins + Terraform으로 자동화된 배포 파이프라인 구성
◦
Blue/Green 배포 (AZ 단위 전환)
◦
Redis(Session/Cache), RDS(Multi-AZ), MSK(Event) 통합
◦
Terraform은 IaC로 모든 리소스를 관리하며, S3 + DynamoDB 를 backend로 사용
3. 네트워크 구조
•
전체 인프라는 AWS VPC 기반의 2-AZ 구조 (AZ-a / AZ-b) 로 설계
•
Public, Private Subnet을 분리하여 트래픽 및 보안 계층화
•
VPC 및 Subnet CIDR은 /16 ~ /24 범위 내에서 결정 예정 (TBD)
구분 | 역할 | 구성 계획 |
Public Subnet | 외부 노출용 리소스 | ALB, NAT Gateway, Bastion |
Private Subnet | 내부 서비스 | ECS Task, RDS, Redis, Jenkins, MSK |
Routing | 인터넷 게이트웨이 / NAT Gateway 사용 | 외부 API 호출은 NAT, 외부 접근은 ALB |
보안 정책 | SG 기반 최소 접근 | ALB 80/443만 외부 허용, RDS/Redis 내부 통신만 |
DNS | Route53 + ACM | HTTPS 통신 기반 인증서 관리 |
4. 애플리케이션 계층
서비스 구조
서비스 | 구성 | 역할 |
Spring Cloud Gateway | API Gateway | 외부 요청 진입점 |
Eureka Server | Service Discovery | MSA 간 라우팅 관리 |
Config Server | Configuration 관리 | Git 기반 설정 및 Kafka Bus Refresh |
User / Product / Order / Payment / AI | ECS Task | 개별 비즈니스 로직 수행 |
서비스 흐름
Client → Route53 → ALB → Gateway
→ Eureka 등록된 MSA 서비스 호출
→ Redis / RDS / S3 / Kafka 연동
→ Response 반환
Plain Text
복사
배포 방식
•
ECS Fargate 기반
•
Terraform + Jenkins 를 통한 자동 배포
•
무중단 Blue/Green 배포 전략 (AZ 단위) 적용
5. 데이터 계층
구성요소 | 설계 의도 |
RDS (PostgreSQL) | Multi-AZ 구성 (Writer: AZ-a, Standby: AZ-b, Reader 다중 구성) |
Redis (ElastiCache) | Session Redis (세션 + 비영속 데이터 저장소) |
Cache Redis (캐시 저장소) | |
MSK (Kafka) | Order  Payment 간 Event 기반 메시징 Payment 간 Event 기반 메시징 |
S3 | Product 이미지 저장소 + CloudFront 배포 원본 |
DynamoDB | Terraform State Lock 관리용 (Backend) |
•
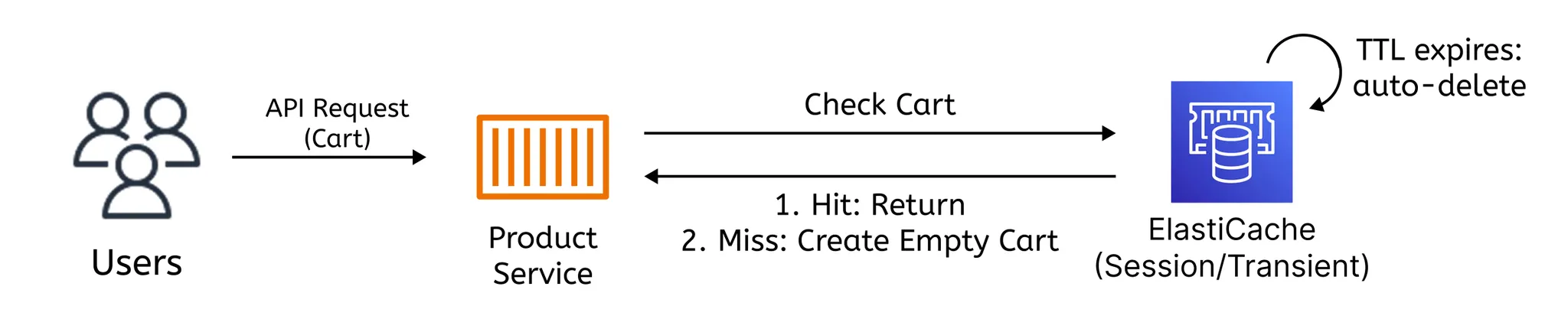
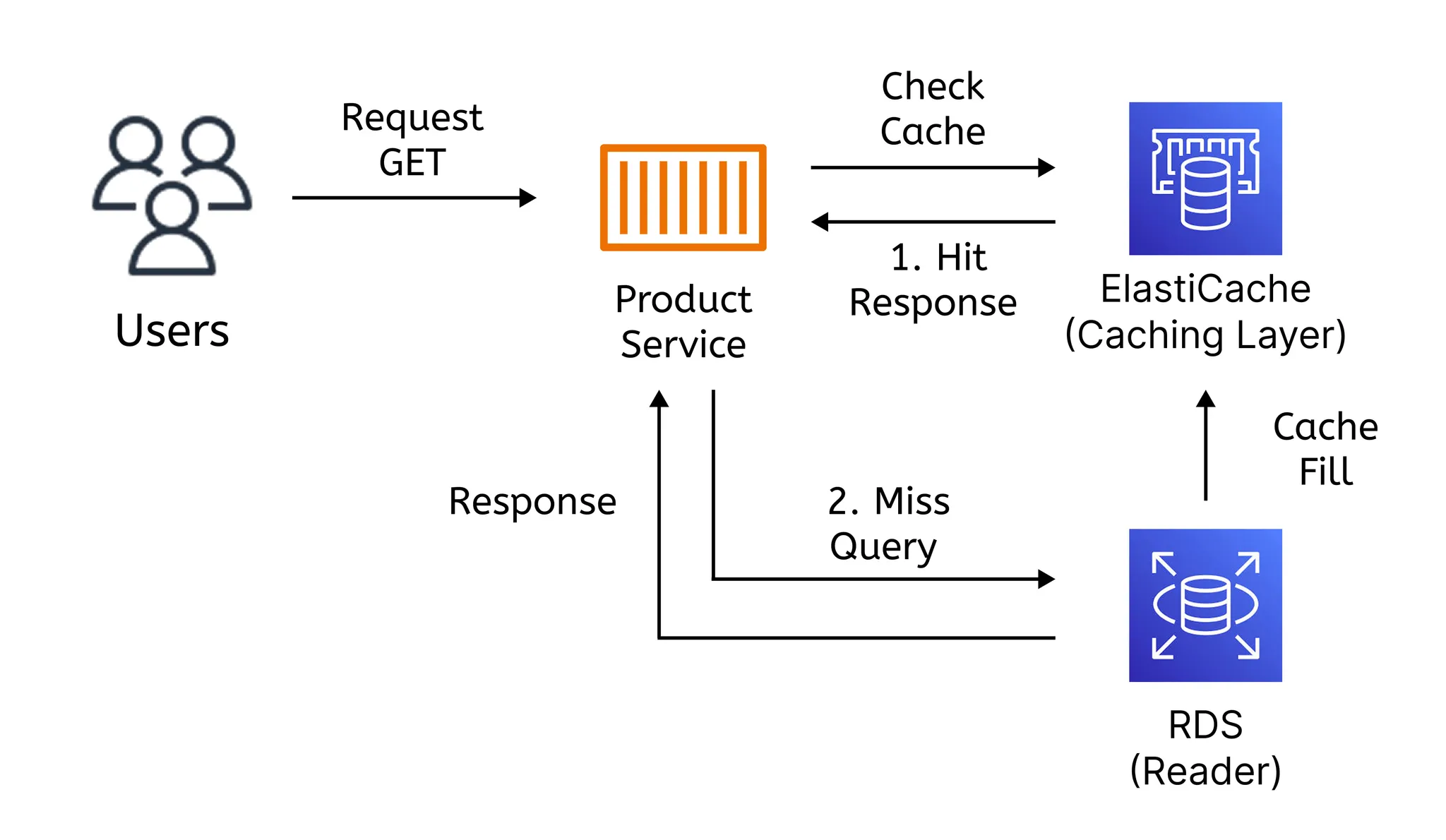
Redis 활용 목적
역할 | 용도 | 데이터 특성 | 요구 사항 |
세션 저장소 (Session Layer) | JWT / Refresh Token / 로그인 상태 관리 | 짧은 TTL, 동시 접근 빈번 | 고가용성 + 빠른 쓰기 |
비영속 데이터 저장소 (Transient Layer) | 장바구니, 쿠폰 임시 저장 | 사용자별, 중단 시 복구 불필요 | 속도 우선, 데이터 유실 허용 가능 |
캐시 저장소 (Caching Layer) | 상품 조회, 목록 페이지 캐싱 | 자주 읽고, TTL 관리 | 읽기 최적화 + 만료 정책 필요 |
6. CI/CD 파이프라인
•
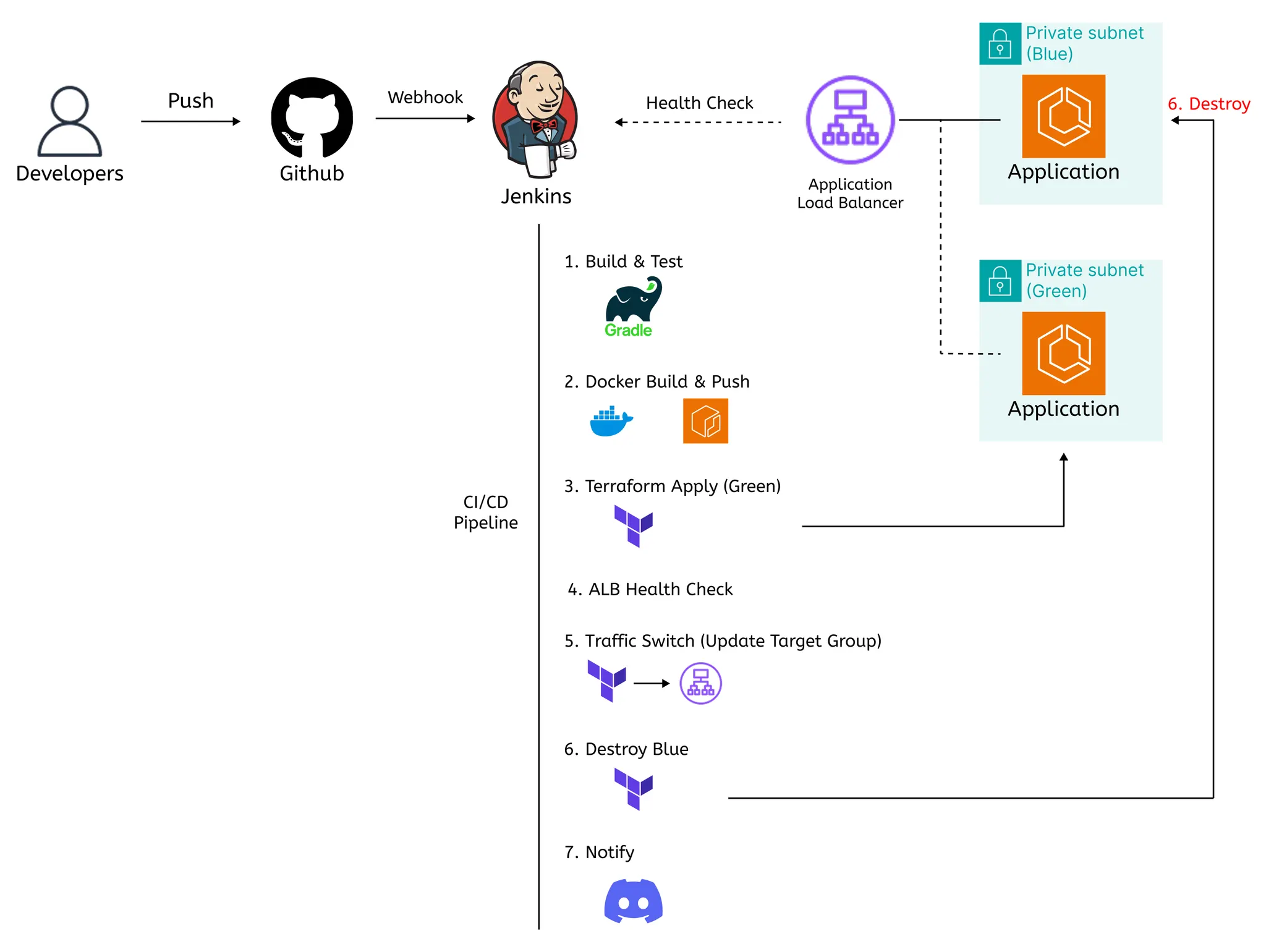
GitHub → Jenkins → Terraform → AWS 순의 자동화 파이프라인
•
Jenkins는 Private Subnet에 위치, ALB를 통해 GitHub Webhook 수신
•
Terraform은 S3 Backend 및 DynamoDB Lock으로 상태 관리
젠킨스 구성
항목 | 설명 |
Storage | EBS Volume (Persistent) |
AMI 관리 | Packer를 통한 Jenkins 이미지 자동화 |
IAM Role | Terraform 및 ECR 접근 전용 Role 분리 |
보안 | Private Subnet + HTTPS ALB Webhook 수신 구조 |
7-1. 배포 전략
설계 의도
Multi-AZ 구조를 활용하여 AZ-a (Blue)와 AZ-b (Green) 간 배포를 전환함으로써
무중단 배포 및 장애 복구 검증 환경 확보
배포 프로세스
단계 | Terraform 상태 | 설명 |
① 초기 배포 | active_color=blue | AZ-a에 Blue 환경 구성 |
② 신규 버전 배포 | active_color=green | AZ-b에 Green 환경 생성 |
③ 헬스체크 | - | ALB Target Group의 Green 상태 확인 |
④ 트래픽 전환 | active_color=green | Listener 전환 (Blue → Green) |
⑤ Blue 종료 | active_color=green 유지 | Terraform에 의해 Blue 자동 destroy |
7-2. 오토스케일링 전략
설계 의도
•
MSA 환경에서 서비스별 트래픽 패턴에 따라 자동 확장/축소(Auto Scaling) 정책을 설정
•
Spring Cloud Core 서비스(Gateway, Eureka, Config Server) 는 시스템의 핵심 구성요소로 항상 가용 상태를 유지해야 하므로 최소 인스턴스 1개(Min=1) 로 유지
•
일반 애플리케이션 서비스(User, Product, Order, Payment, AI)는 트래픽 변화에 대응하면서 비용 효율성을 극대화하기 위해 Max 인스턴스 제한을 설정하여 과도한 확장을 방지
서비스 구분 | Scaling 방식 | Min Task | Max Task | 비고 |
Spring Cloud Gateway | 고정 최소 유지 | 1 | 2 | 트래픽 진입점, 항상 가동 필요 |
Eureka Server | 고정 최소 유지 | 1 | 2 | Service Discovery 핵심 |
Config Server | 고정 최소 유지 | 1 | 2 | 모든 서비스 구성 관리 |
User Service | 자동 확장 | 1 | 4 | 로그인/회원 요청 중심 |
Product Service | 자동 확장 | 1 | 6 | 조회 트래픽 집중, 캐시 연계 |
Order Service | 자동 확장 | 1 | 4 | 결제 요청, 비동기 이벤트 처리 포함 |
Payment Service | 제한적 확장 | 1 | 3 | 외부 결제 API 연동 고려 |
AI Service | 수동 확장 | 1 | 2 | 비정기 호출, 필요 시 수동 배포 |
7-3. 고려사항 (고민점)
Fargate 기동 지연(Cold Start)에 대한 고려사항
ECS를 Fargate 기반으로 구성하면서, Scale-Out 시 새 Task가 시작될 때 발생할 수 있는 Cold Start 문제를 인지하고 있음.
현재 Gateway, Eureka, Config Server 등 항상 가용 상태를 유지해야 하는 핵심 서비스는 최소 인스턴스 수(Min=1)로 설정하여 이러한 영향을 최소화하고 있음.
다만, Product / Order / Payment 등 트래픽 변화에 따라 동적으로 확장되는 서비스의 경우 Task 프로비저닝 및 컨테이너 초기화 과정에서 수 초~수십 초의 지연이 발생할 수 있어,
다음과 같은 추가 전략을 검토 중:
•
HealthCheckGracePeriodSeconds 조정 (60~120초)
•
Scheduled Scale-Out(예측 트래픽 기반 사전 확장)
•
이미지 크기 최적화 및 캐시 레이어 강화
1.
Fargate의 Cold Start 지연이 실제 사용자 응답 속도에 유의미한 영향을 줄까?
2.
일정 Task를 상시 유지(Warm Instance)하는 전략이 비용 대비 효과적인가?
8. 모니터링
구성요소 | 설계 내용 |
CloudWatch Logs | ECS Task / Jenkins / Lambda 로그 집계 |
Metrics | ECS CPU/Mem, RDS Connection, Redis Ops/sec, Kafka Lag |
Alarms | SNS → Lambda → Discord Webhook 알림 |
Dashboard | CloudWatch + Grafana 통합 가능성 고려 |
9. 고가용성 및 장애 복구
구성요소 | 설계 의도 |
ECS | Multi-AZ 구조 유지, 배포 시 1AZ만 활성 |
RDS | Multi-AZ + 자동 Failover |
Redis(Session) | Multi-AZ Primary/Replica 구성 |
Jenkins | EBS Snapshot 기반 복구 가능 |
10. 비용 관리
항목 | 전략 |
ECS | 배포 시 일시적 2배 리소스, 평상시 단일 AZ 운영 |
NAT Gateway | Dev/Stage는 NAT 1개만 유지 |
Redis(Cache) | ClusterMode Disabled (단일 노드 구성) |
CloudWatch | Logs 보관 주기 30일 |
RDS Replica | Writer/Reader DB 분리, Standby 적용 X |
비용 모니터링 | AWS Cost Explorer 및 AWS Budgets, AWS CloudWatch Billing Alarms 연동 |
비용 알림 | AWS SNS → Slack / Discord Webhook 으로 월간 예산 초과·급등 알림 자동 전송 |
11. DR
구성 요소 | 설계 방안 |
RDS | 자동 Snapshot + Multi-AZ Failover |
EBS (Jenkins) | Snapshot 기반 복구 |
Terraform | S3 Backend 기반 전체 인프라 복원 |
S3 | Versioning + Lifecycle Policy |
CloudWatch | 장애 알림 → Discord Notification Trigger |
12. 확장 설계 방향
항목 | 계획 | 설계 의도 |
EKS 전환 | ECS → EKS 마이그레이션 | Kubernetes 기반의 오케스트레이션으로 유연한 스케일링 및 커스텀 리소스 관리 도입 |
CI/CD 파이프라인 변화 | Jenkins → ArgoCD 기반 GitOps 전환 | 선언적 배포(GitOps)로 환경 일관성 확보 및 Rollback 자동화, Multi-env 배포 관리 단순화 |
Service Mesh (Istio) | Istio 적용 (Ingress + mTLS + Observability) | 서비스 간 통신 보안, 트래픽 제어, 분산 추적 및 모니터링 강화 |
WAF / Shield | CloudFront 보안 레이어 강화 | DDoS 방어, Bot 필터링, OWASP Top10 대응 |
확장 전환 로드맵
단계 | 전환 내용 | 주요 포인트 |
1단계 – 현행 구조 (ECS + Jenkins + Terraform) | ECS Fargate + Terraform Blue/Green | IaC 자동화 및 안정적인 CI/CD 기반 확립 |
2단계 – EKS 전환 (Kubernetes Adoption) | EKS Cluster 구축 → 기존 서비스 점진적 이관 | Pod 기반 배포, Helm/Kustomize로 관리 단위 세분화 |
3단계 – GitOps 전환 (ArgoCD 도입) | Jenkins의 Terraform Apply 중심 구조 → ArgoCD GitOps 구조 | 배포 선언화(Declarative Deployment), Git Repository 중심 상태 관리 |
4단계 – Service Mesh 적용 (Istio) | Istio 설치 및 Sidecar Proxy 자동 주입 | 서비스 간 통신 암호화(mTLS), 트래픽 분산, Observability 확립 |
5단계 – 운영 고도화 (Monitoring/Cost) | Prometheus + Grafana + Loki / Karpenter 도입 | 모니터링/로깅 고도화 및 자동 노드 스케일링으로 비용 효율 극대화 |