Role: Infra & DevOps — 아키텍처 설계 | 인프라 구축 | CI/CD | Istio 도입
Period: 2025.10 – 2025.12
Stack: AWS EKS ∙ Terraform ∙ Istio ∙ ArgoCD ∙ Jenkins ∙ Prometheus ∙ Grafana ∙ Loki
Link: [GitHub] [RCA Report]
1. 프로젝트 소개
COME2US는 트래픽 증가 상황을 가정한 MSA 기반 전자상거래 플랫폼입니다.
단순히 서비스를 Kubernetes 위에 올리는 것이 아니라, 서비스가 늘어날수록 반복적으로 발생하는 배포, 인증∙인가, 트래픽 제어, 시크릿 관리 문제를 서비스 코드 바깥의 공통 플랫폼 레이어로 끌어올리는 것에 집중했습니다.
초기에는 Monolith로 빠르게 MVP를 검증했고, 이후 ECS Fargate 기반 MSA로 서비스를 분리하며 독립 배포와 확장을 시도했습니다. 하지만 서비스 수가 늘어나면서 서비스 디스커버리, 공통 정책 관리, 배포 운영 방식이 구조적으로 복잡해졌고, 이를 해결하기 위해 최종적으로 EKS 기반 Cloud-Native 환경으로 전환했습니다.
이 과정에서 Kubernetes 선언형 리소스와 GitOps, Service Mesh를 활용해 서비스별 구현에 흩어질 수 있는 운영 책임을 플랫폼으로 공통화하는 방향으로 구조를 재설계했습니다.
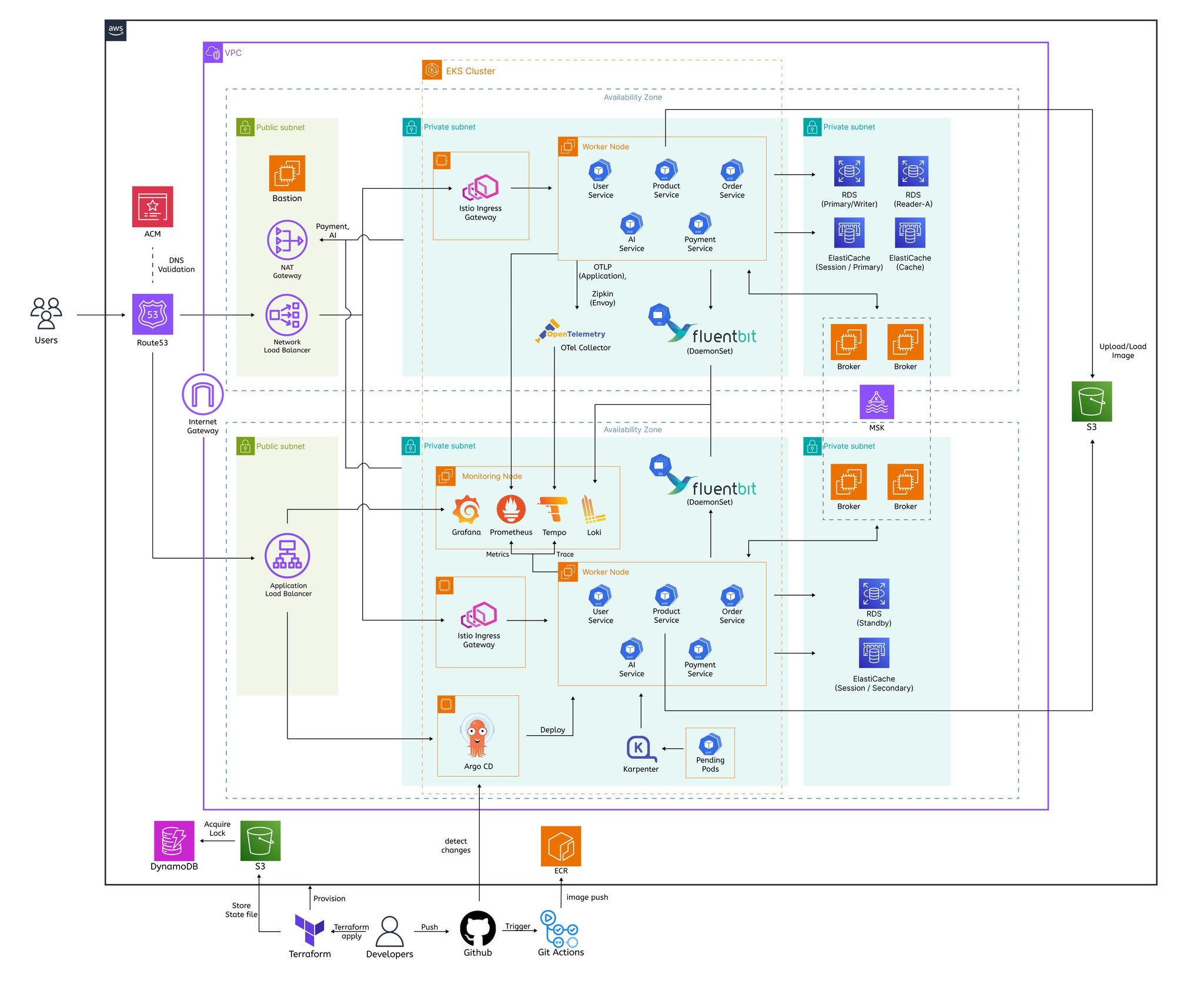
[이미지 1] Event-Driven MSA Architecture
2. 왜 플랫폼이 필요했는가
COME2US의 아키텍처는 각 단계에서 실제로 드러난 운영 문제를 근거로 다음 단계로 전환되었습니다.
Phase 1. Monolith
초기 구조는 단일 EC2 위에 애플리케이션을 Docker 컨테이너로 배포해 MVP를 빠르게 검증했습니다. 개발 속도는 확보할 수 있었지만, 두 가지 구조적 문제가 분명했습니다.
•
확장성 한계 — 특정 서비스에만 부하가 증가해도 서버 전체를 키워야 하는 수직 확장에 의존
•
장애 전파 — 서비스 간 경계가 없었기 때문에 하나의 서비스 장애가 동일 서버의 다른 기능에도 영향을 줄 수 있는 구조
→ 서비스 독립성과 수평 확장을 위해 MSA + ECS로 전환했습니다.
Phase 2. ECS Fargate 기반 MSA
서비스를 독립 컨테이너로 분리하면서 장애 격리와 서비스 분리는 개선되었지만, 서비스 수가 늘어나면서 새로운 운영 부담이 생겼습니다.
•
ECS Fargate의 서비스 디스커버리 문제
◦
ECS의 내부 IP/외부 IP의 차이로 기반 서비스 디스커버리가 정상 동작하지 않음
◦
일시적으로 hostname을 환경변수로 주입하는 방식으로 대응 → 운영 확장성 떨어짐
•
공통 정책 관리의 한계 — 인증∙인가∙라우팅∙필터링∙트래픽 제어 등의 공통 정책이 Spring Cloud Gateway와 애플리케이션 레벨에 묶임 → 정책 변경이 코드 변경과 재배포로 이어짐
→ 공통 정책을 플랫폼 레이어에서 통합 처리하기 위해 EKS 기반 Cloud-Native 전환 결정
Phase 3. EKS 기반 Cloud-Native 플랫폼
핵심 목표는 서비스를 단지 컨테이너로 실행하는 것이 아니라, 배포 방식과 공통 정책을 선언적으로 관리할 수 있는 운영 기반을 만드는 것이었습니다.
서비스별로 흩어져 있던 정책을 Kubernetes와 Istio 기반 리소스로 통합하고, 변경이 필요할 때마다 애플리케이션을 수정하는 대신 ‘Manifest PR → ArgoCD Sync’ 흐름으로 반영되는 구조를 설계했습니다.
3. 플랫폼 기능 구현
3-1. Delivery Platform — 배포 방식의 표준화
서비스 수에 상관없는 배포 일관성을 가지도록 했습니다.
Phase 1. GitHub Actions — 단일 서비스 CI
Phase 2. Jenkins Shared Library — 공통 CI 표준화 + Terraform 연계 Blue/Green 배포
Phase 3. GitHub Actions(CI) + ArgoCD(CD) — 역할 분리, GitOps 기반 선언적 배포
구조가 Monolith → ECS → EKS로 고도화되면서, 배포 방식도 단순 자동화 수준에서 운영 효율성과 재현성을 확보하는 방향으로 함께 발전시켰습니다. 핵심 목표는 서비스 수 증가에 따른 파이프라인 관리 비용을 줄이고, 인프라 변경과 애플리케이션 배포를 더 일관된 방식으로 운영하는 것이었습니다.
 단일 서비스 CI — GitHub Actions
단일 서비스 CI — GitHub Actions초기에는 GitHub Actions로 단일 서비스 CI를 구성했지만, MSA 전환 이후 서비스별로 별도 파이프라인이 생기면서 중복 코드와 관리 비용이 증가했습니다.
공통 CI 표준화 — Jenkins Shared Library마이크로서비스 환경에서 서비스 수 증가에 따라 파이프라인 중복과 관리 포인트가 늘어났습니다.
이를 해결하기 위해 Jenkins Shared Library를 도입하여 공통 CI 로직을 표준화했습니다. 빌드∙테스트, 이미지 빌드 및 푸시, 알림 흐름을 공통화했고, Gradle 빌드 캐시와 Docker BuildKit 레이어 캐시를 적용해 반복 빌드 효율도 함께 개선했습니다.
•
Shared Library를 활용해 서비스별 Jenkinsfile 중복을 줄이고 공통 배포 로직을 표준화
•
Blue/Green 배포로 무중단 전환
CI 빌드
→ Warm-up 서비스 생성
→ Health Check
→ ALB Target Group 전환
→ 이전 환경 정리
Plain Text
복사
•
BuildKit, Gradle Cache 적용을 통해 빌드 시간을 약 95% 단축
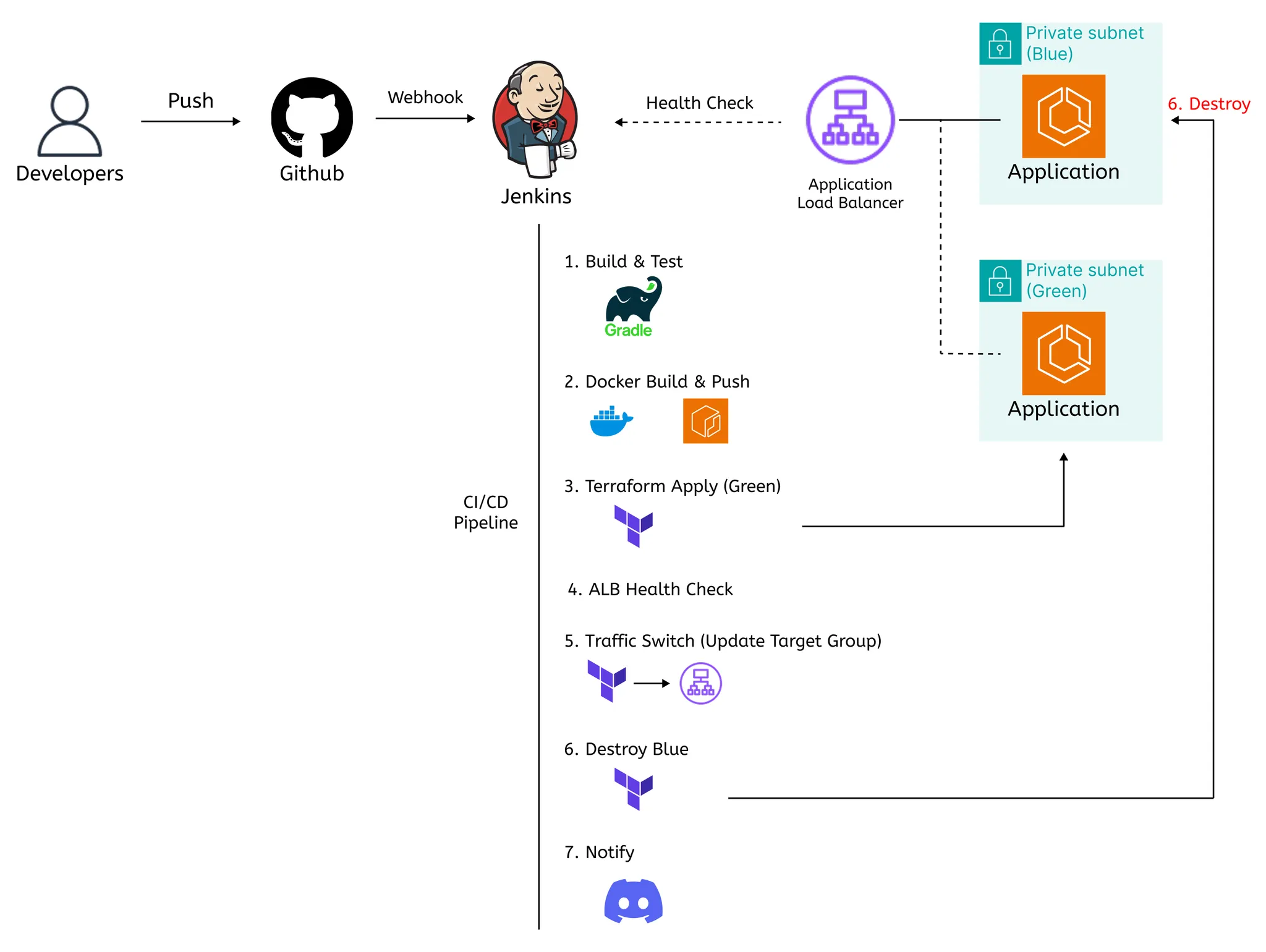
[이미지 2] CI/CD 파이프라인 흐름도
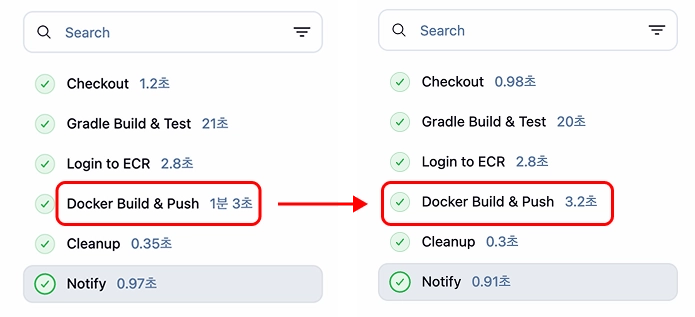
[이미지 3] Docker Layer Cache 적용 전/후: 1분 3초 → 3.2초 단축
GitOps 파이프라인 구축이후 Jenkins 자체가 별도 운영 대상이 되면서 CI와 CD의 책임을 다시 분리했습니다. CI는 GitHub Actions가 담당하고, CD는 ArgoCD와 Helm Chart 기반 GitOps 구조로 분리해 클러스터 상태를 Git 기준으로 선언적으로 수렴시키는 운영 모델을 구축했습니다.
•
GitHub Actions: 이미지 빌드 및 레지스트리 푸시
•
ArgoCD: Git 상태를 기준으로 Kubernetes 리소스를 선언적으로 동기화
•
External Secrets + SSM Parameter Store: 애플리케이션 시크릿을 Git 저장소와 분리하여 관리
배포 파이프라인에서 서버 운영 부담을 줄이고, 인프라와 애플리케이션 변경을 GitHub를 단일 지점으로 설계했습니다.
3-2. Policy as Platform — 인증∙인가∙라우팅 정책의 공통화
정책 변경이 서비스 재배포를 요구하지 않는 구조를 만드는 것을 목표했습니다.
ECS 단계에서 Spring Cloud 컴포넌트에 대한 의존성과 운영 복잡도를 경험하면서, 인증∙인가∙라우팅 같은 공통 정책은 애플리케이션 코드보다 플랫폼 계층에서 관리하는 것이 더 적절하다고 판단했습니다.
이를 위해 Istio를 단순 프록시가 아닌 정책 제어 평면(Control Plane)으로 활용했습니다.
•
RequestAuthentication(JWKS) + AuthorizationPolicy로 JWT 검증과 권한 처리를 Ingress 레이어에서 통합 처리 → 서비스 코드의 인증 의존 제거
•
Gateway/VirtualService로 라우팅 정책을 선언적으로 관리 → 정책 변경을 Manifest PR 단위로 처리
•
서비스 간 mTLS 적용으로 내부 통신 보안 강화
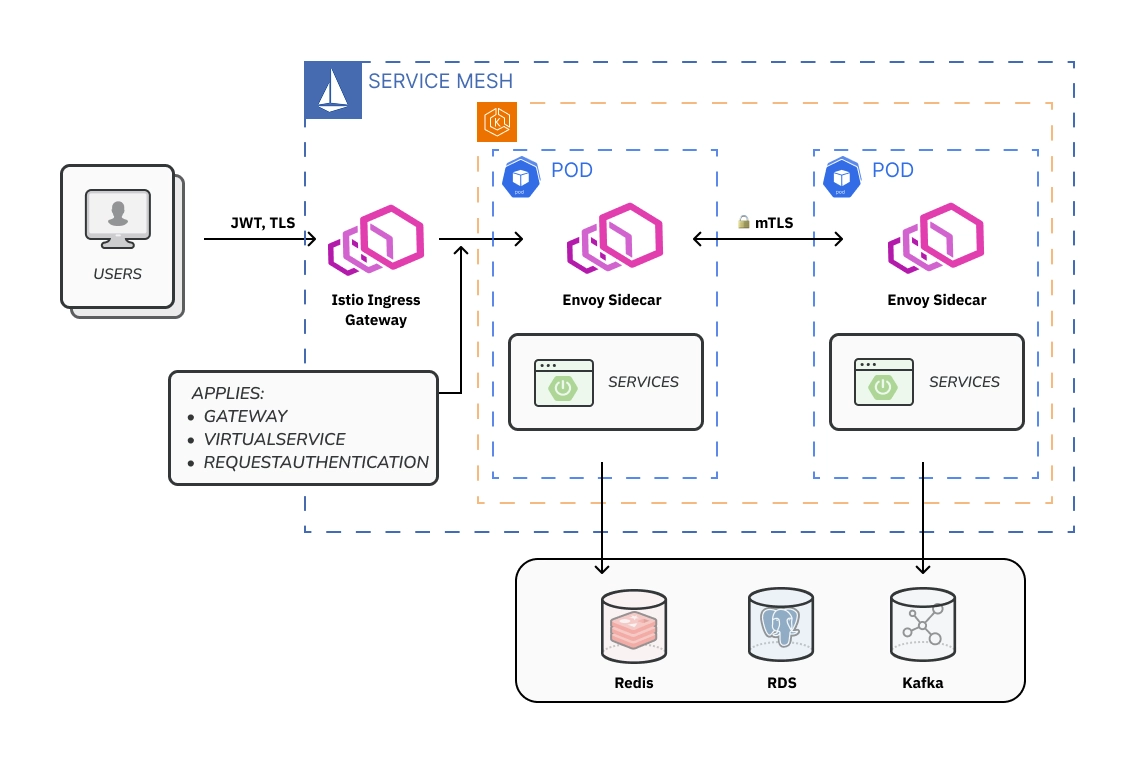
[이미지 4] Istio 서비스 흐름
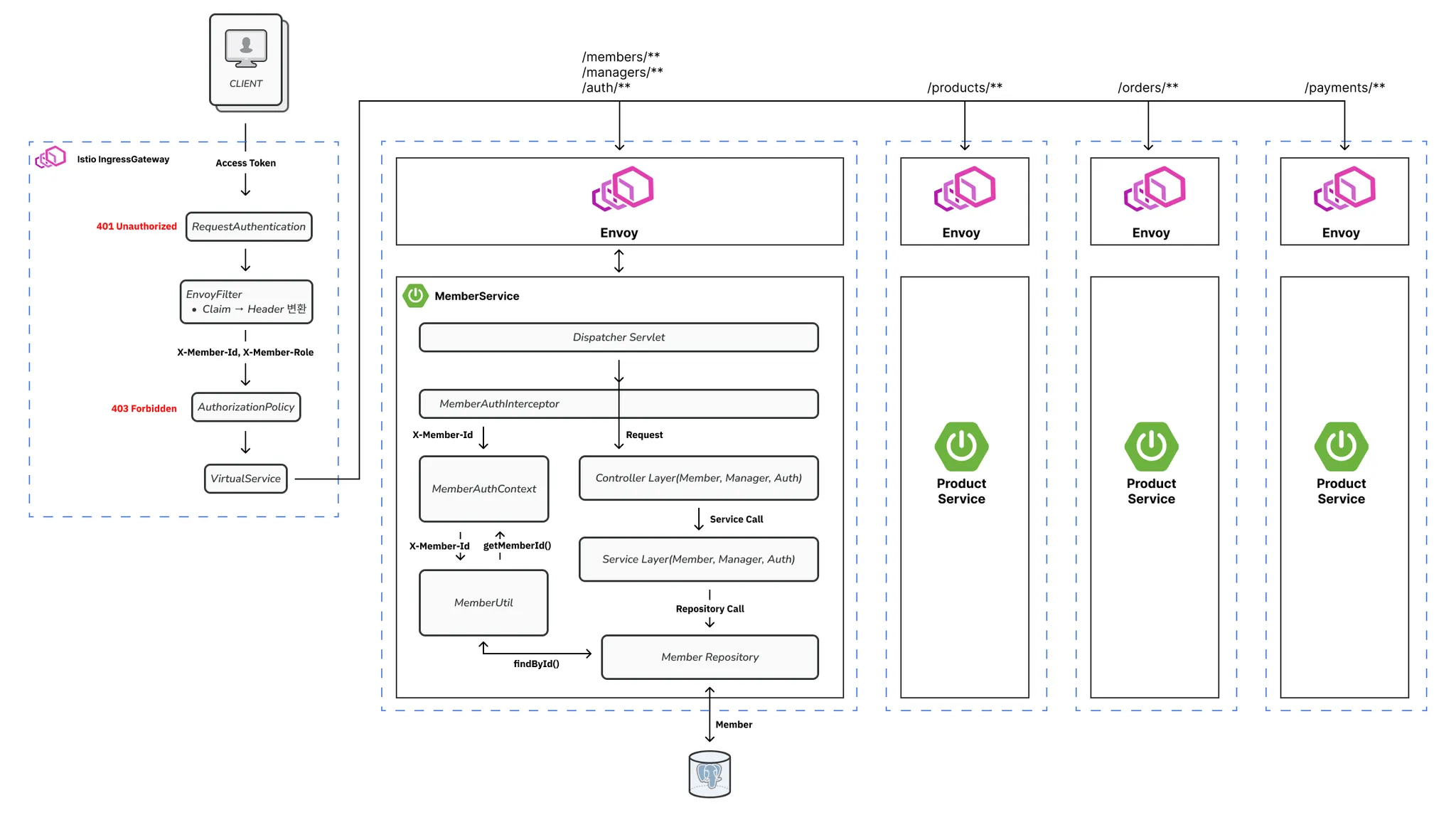
[이미지 5] Istio JWT 인증 흐름
→ Spring Cloud 컴포넌트를 제거하고 정책 변경 단위가 Manifest PR 1회로 전환되었습니다.
3-3. Runtime Platform — 공통 실행 환경 표준화
단순히 배포만 자동화하는 것이 아닌, 서비스가 안정적으로 실행될 수 있는 공통 런타임을 제공했습니다.
EKS 환경에서는 Kubernetes 선언형 리소스를 기반으로 서비스 운영 방식을 표준화했습니다.
노드 그룹 분리 — 플랫폼 컴포넌트 안정성 우선노드 그룹 | 운영 방식 | 목적 |
Infra Node Group | On-Demand | Karpenter · ArgoCD · Istio · 모니터링 등 핵심 운영 컴포넌트 안정성 확보 |
App Baseline Node Group | On-Demand | 일반 트래픽 구간의 기본 애플리케이션 처리 용량 보장 |
Dynamic Node | Karpenter + Spot | 트래픽 증가 시 비용 효율적인 확장 처리 |
•
infra 노드 그룹에는 Taint를 적용해 핵심 운영 컴포넌트가 애플리케이션 부하에 밀려 Pending 상태가 되는 상황을 방지했습니다.
•
애플리케이션 워크로드는 평상시에는 On-Demand 기반 노드에서 안정적으로 운영하고, 트래픽 증가 구간에서는 Karpenter가 Spot 노드를 동적으로 프로비저닝해 확장하도록 구성했습니다.
•
Karpenter Spot Interruption은 SQS + EventBridge로 감지하여 선제적으로 대체 노드를 프로비저닝하는 구조를 갖춰 Spot Instance로 발생할 수 있는 장애를 대비했습니다.
이 구조를 통해 기본 안정성을 유지하며 빠른 프로비저닝과 약 70% 비용 절감 효과를 얻을 수 있었습니다.
배포 대상은 Manifest와 Helm Chart로 관리하고, 변경은 Git 단위로 추적되도록 구성함으로써, 운영이 개인에 의존하지 않고 동일한 방식으로 워크로드를 배포하고 유지할 수 있는 환경을 만들었습니다.
3-4. Observability Platform — 운영 가시성 확보
Service Mesh를 도입하며 서비스 간 호출 흐름을 추적해 장애를 해석할 필요가 생겼습니다. 이를 위해 메트릭∙로그∙트레이스를 통합하는 관측성 체계를 구성했습니다.
Metric | Prometheus → Grafana |
Log | Fluentbit → Loki → Grafana |
Trace | OTel → Tempo → Grafana |
OTel 트레이싱 연동으로 Mesh 내부 호출 흐름을 추적할 수 있도록 했고, 플랫폼 변경이 실제 운영에 어떤 영향을 주는지 확인할 수 있는 기반을 마련했습니다.
수집 지표•
CPU∙Memory∙Disk I/O 등 시스템 메트릭
•
HTTP 응답 시간 및 상태값
•
서비스 간 호출 경로∙지연시간∙에러율
3-5. Platform Provisioning — 플랫폼 운영의 재현성과 지속성 확보
Infra as Code플랫폼은 배포 도구나 서비스 메시만으로 완성되지 않고, 그 위에서 서비스가 실행될 수 있는 기반 인프라까지 일관된 방식으로 관리되어야 한다고 보았습니다.
COME2US에서는 AWS 인프라와 Kubernetes 실행 기반을 Terraform으로 구성해, 플랫폼의 하부 기반 역시 수작업이 아니라 코드로 관리하는 방향을 택했습니다.
come2us-eks/
├── bootstrap/ # S3 버킷, DynamoDB 락 테이블, IAM 초기 구성
├── dns/ # Route53 Hosted Zone, ACM 인증서 (별도 state)
│ └── backend.hcl
├── modules/
│ ├── network/ # VPC, 서브넷, 라우팅 테이블, NAT Gateway, IGW
│ ├── sg/ # 보안 그룹
│ ├── bastion/ # EC2 + SSM IAM Role
│ ├── rds/ # PostgreSQL RDS
│ ├── elasticache/ # Redis
│ ├── iam/ # EKS Access Entry, IRSA 연계
│ ├── ssm/ # SSM Parameter Store
│ ├── route53/ # Hosted Zone, 레코드, 인증서 연계
│ └── msk/ # MSK Kafka
├── eks.tf # EKS 클러스터
├── karpenter.tf # Karpenter module
├── iam.tf # IRSA (ALB Controller, ExternalDNS, External Secrets)
├── ...
└── scripts/
├── tunnel.sh # SSM 포트포워딩 터널
└── bootstrap-k8s.sh # ALB Controller, ArgoCD 초기 설치
Plain Text
복사
Karpenter NodePool 등 클러스터 내부 리소스는 ArgoCD로 관리해 Terraform은 인프라 레이어, GitOps는 클러스터 레이어로 경계를 명확히 분리했습니다.
Packer프로젝트 환경에서는 비용 제약으로 인해 AWS 리소스를 자주 Destroy/Recreate해야 했고, 그 과정에서 Jenkins 서버와 설정을 매번 다시 구성해야 하는 문제가 있었습니다. 이로 인한 휴먼 에러, 드리프트 제거를 위해 Packer를 사용했습니다.
Packer로 Docker가 사전 구성된 Golden AMI를 빌드하고, Terraform으로 EC2∙EBS∙ALB 노출∙Jenkins 컨테이너 기동까지 자동화했습니다. 그 결과 terraform apply만으로 CI 환경을 반복적으로 재구성할 수 있는 운영 모델을 만들었습니다.
4. 의사 결정 및 Trade-off
Istio 도입
Istio 도입은 오버엔지니어링으로 이어질 수 있으며 운영 복잡도, 학습비용의 증가를 가져오지만, 정책 변경 리드타임, 공통 보안 정책 일관성을 고려했을 때 플랫폼 계층으로의 이관이 장기적으로 더 유리하다고 판단했습니다. 또한 E-Commerce 서비스 특성상 신뢰성 있는 서비스 간 통신이 중요하다고 판단해, 서비스 간 통신에 mTLS를 적용하여 보안 수준도 함께 강화하고자 했습니다.
GitOps 도입
배포를 수동 절차나 특정 운영자의 기억에 의존시키지 않기 위해 Git을 단일 진실 공급원(Single Source of Truth)으로 삼았습니다. 변경 이력 추적, 재현성, 선언적 배포라는 장점이 있었고, 특히 정책 리소스와 서비스 배포를 같은 운영 원칙 아래 관리할 수 있다는 점이 중요했습니다.
CI / CD 역할 분리
Jenkins는 복잡한 파이프라인을 통합하는 데 유리했지만 자체 운영 부담이 새로운 비용이 되었습니다. 최종적으로 GitHub Actions가 빌드와 검증을 담당하고, ArgoCD가 배포와 상태 수렴을 담당하도록 역할을 분리했습니다. 플랫폼을 단순화하면서도 각 도구의 역할을 명확히 나누기 위해 최종 전환을 결정했습니다.
5. 트러블슈팅
Issue 1. HPA + Karpenter Race Condition
상황Karpenter 도입 시, HPA에 의해 Pod가 증가하더라도 신규 노드가 Ready 상태가 되기까지는 시간이 필요하다는 점을 고려했습니다. 이에 따라 급격한 트래픽 증가 상황에서는 일시적인 Pending이 발생할 수 있다고 판단했습니다.
원인HPA는 메트릭을 감지하는 즉시 Pod 생성을 요청하지만, Karpenter는 새로운 노드를 프로비저닝하는 데 약 60초가 소요됩니다. 노드가 Ready 상태가 되기 전 Pod 스케줄 요청이 들어올 경우 스케줄러가 배치할 노드를 찾지 못해 Pending이 누적됩니다.
대응핵심 서비스와 비핵심 서비스의 중요도를 구분해 minReplicas를 차등 적용해 기본 버퍼를 확보했습니다.
•
주문∙결제: 높은 minReplicas로 기본 처리 여유 확보
•
조회성 서비스: 낮은 minReplicas로 비용 효율 유지
기대 효과핵심 도메인 서비스는 급격한 스케일 아웃 상황에서도 초기 처리 여유를 확보하고, 전체적으로는 비용과 안정성 간 균형을 맞추는 예방적 설계를 의도했습니다.
Issue 2. Jenkins Node Hang 장애 RCA
상황CI 환경에서 Docker 이미지 빌드 중 Jenkins UI가 504 Error을 반환하고, 이후 SSH 접속이 불가능해지며 Hang 상태로 전환되는 문제가 발생했습니다. CPU·Memory는 정상 범위였기 때문에 단순한 리소스 부족이 아닌 다른 병목 가능성을 의심했습니다.
원인 분석CloudWatch 지표를 통해 다음과 같은 현상을 확인했습니다.
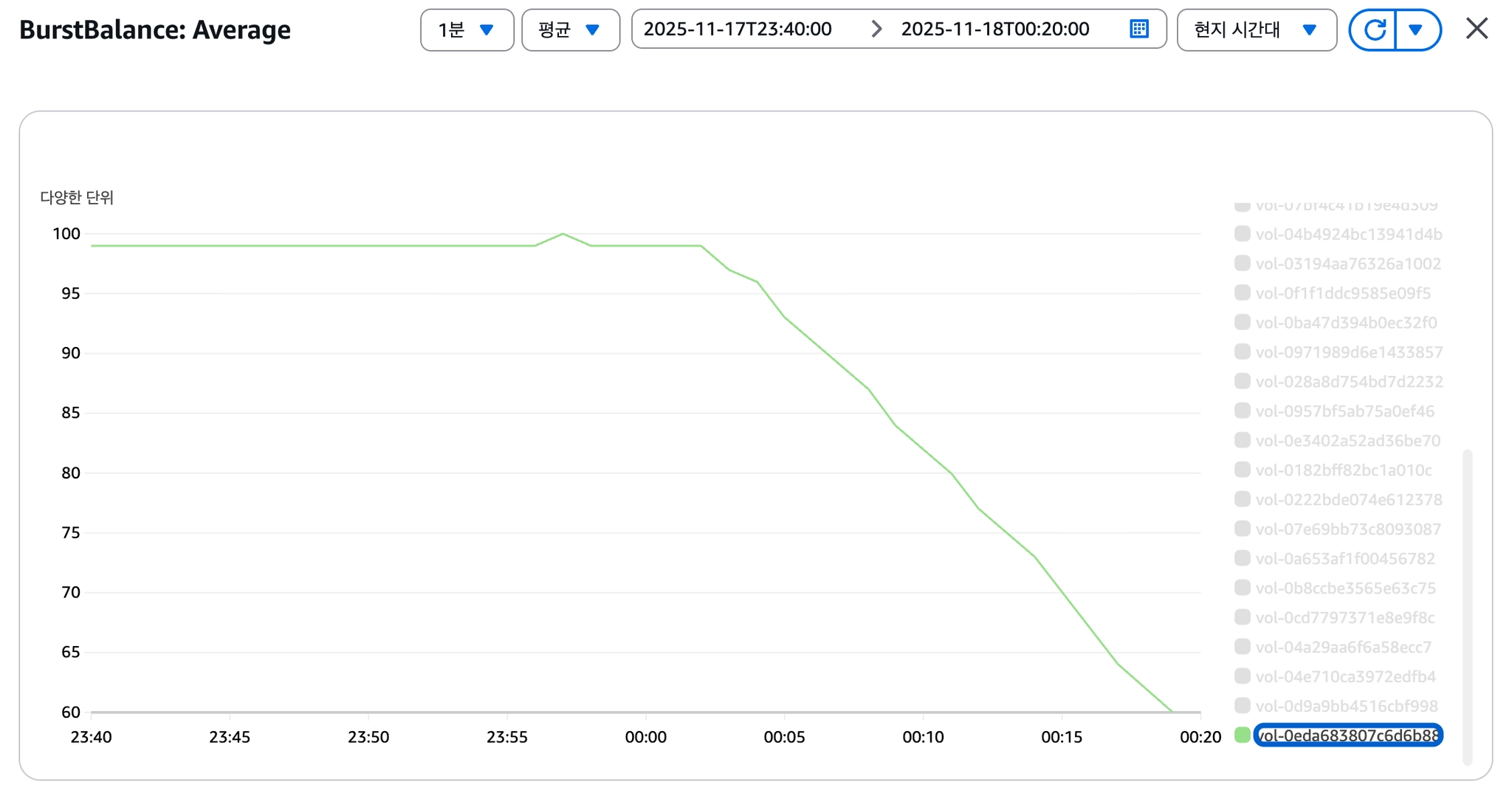
[이미지 6] BurstBalance 고갈
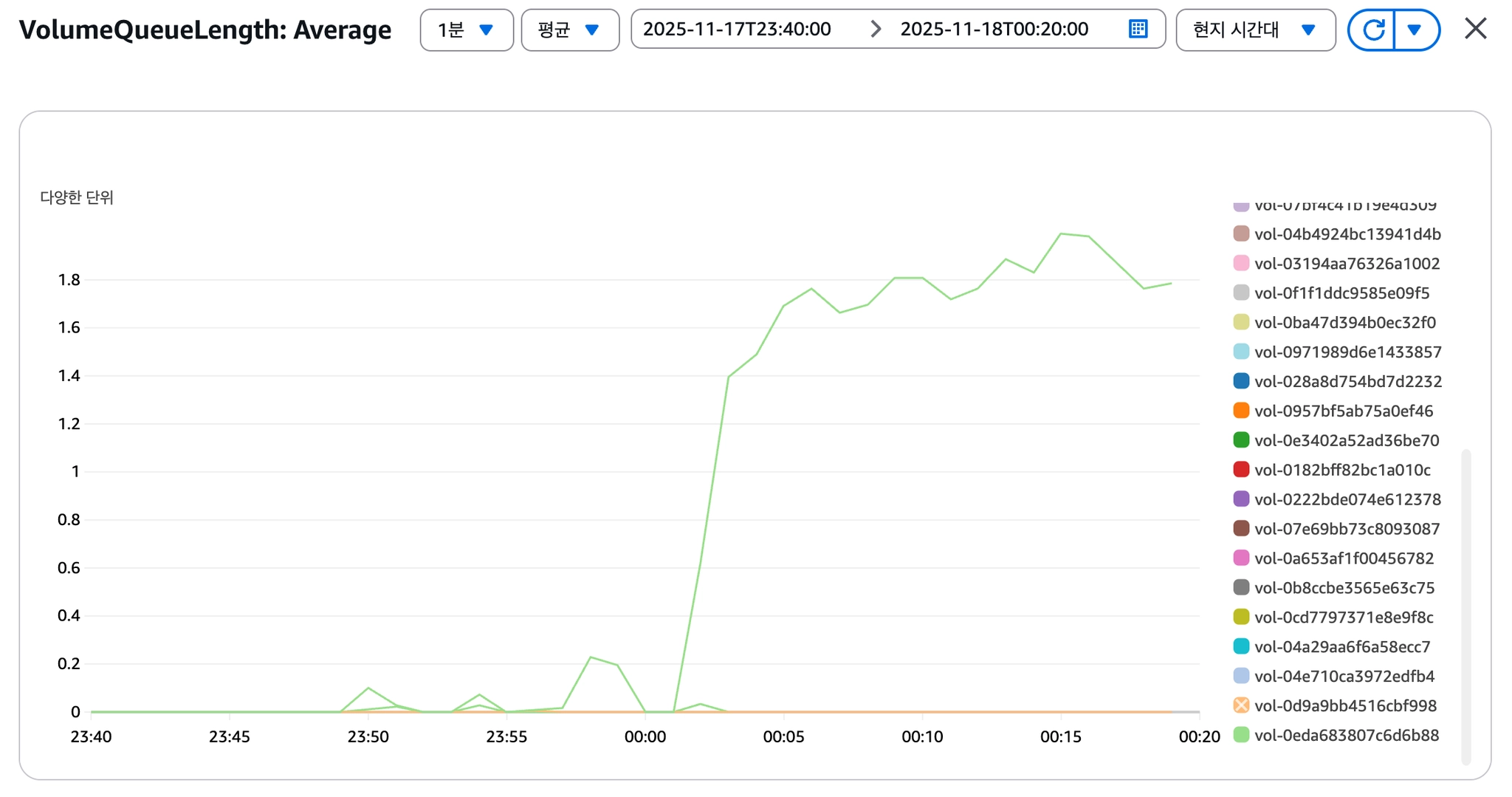
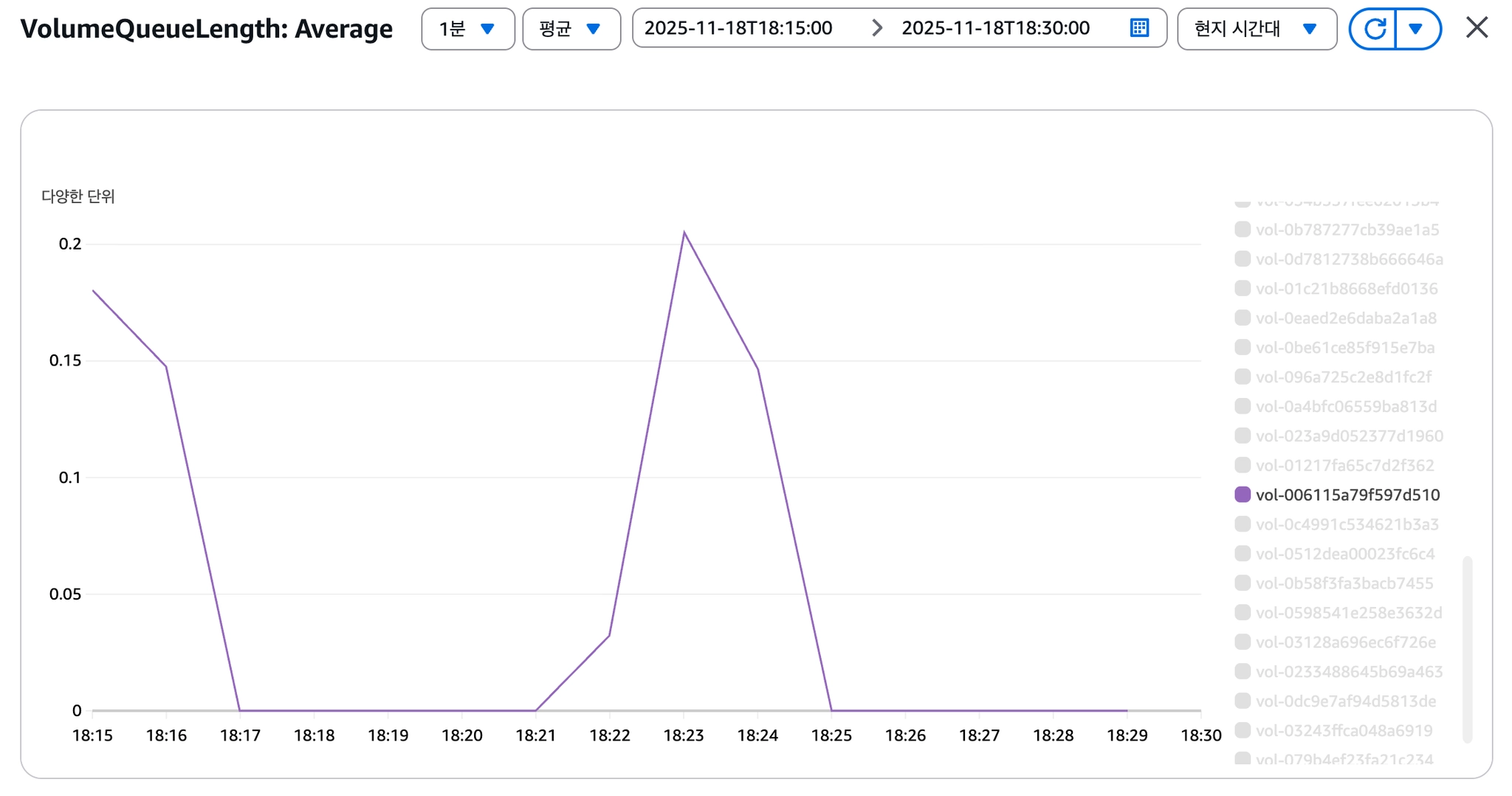
[이미지 7] VolumeQueueLength 급증
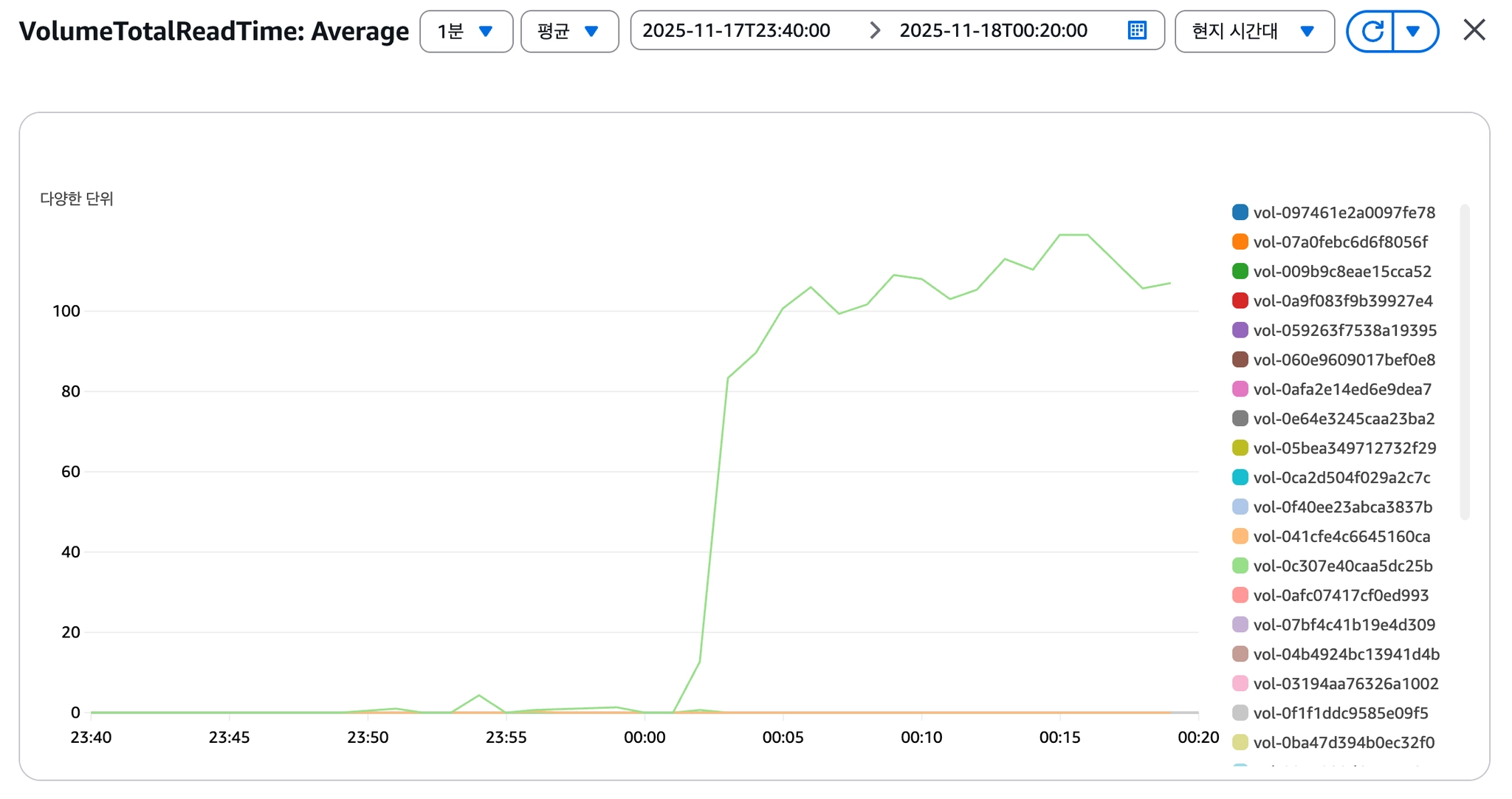
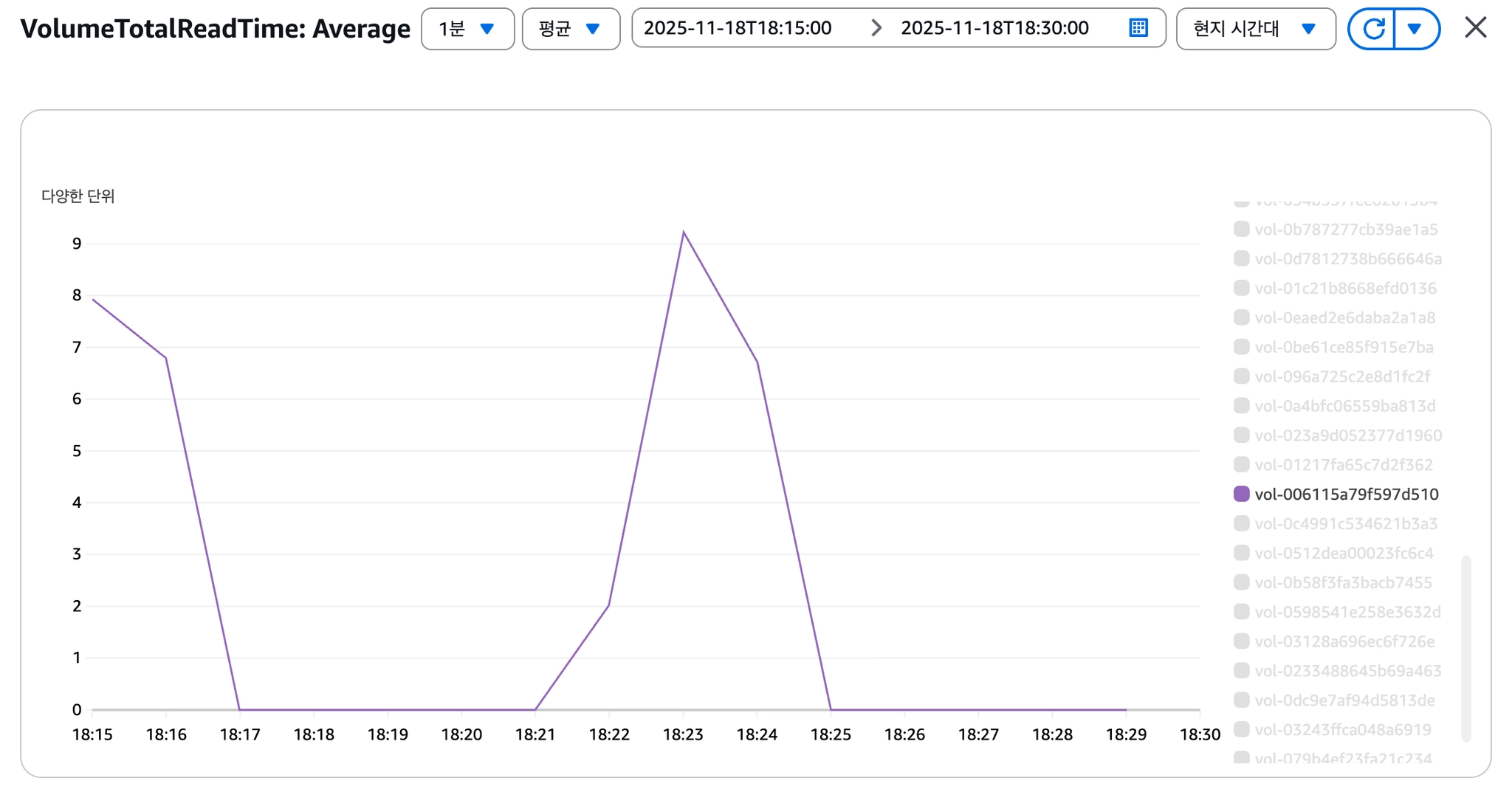
[이미지 8] VolumeTotalReadTime 급증
•
BurstBalance 고갈
•
VolumeTotalReadTime 급증
•
VolumeQueueLength 급증
단일 Root EBS(gp2)에서 OS I/O와 Docker I/O가 경합하고 있었고, gp2의 크레딧 기반 IOPS 구조가 한계에 도달한 것으로 판단했습니다.
→ gp2 볼륨의 IOPS Throttling을 근본 원인으로 규명
해결1.
Root/Data 볼륨 분리 → 빌드 워크로드의 I/O 영향을 OS 레이어와 격리
2.
gp3 전환 → 크레딧 기반 가변 IOPS에서 고정 IOPS 구조로 전환
결과•
Jenkins 504 / Node Hang 현상 해소
•
VolumeQueueLength, VolumeTotalReadTime 지표 안정화
[이미지 9] QueueLength 안정화 (피크 후 안정화)
[이미지 10] TotalReadTime 안정화 (피크 후 안정화)
이 경험을 바탕으로 EKS 환경에서는 gp3를 Default StorageClass로 채택해 동일 문제를 사전에 차단했습니다.
6. 결과 및 성과
플랫폼 레이어 성과
항목 | 변화 |
인증∙인가∙라우팅 정책 | 서비스 코드 분산 → Istio 기반 플랫폼 레이어 공통화 |
정책 반영 방식 | 애플리케이션 재배포 중심 → Manifest PR 기반 반영 |
Spring Cloud 의존 | Gateway∙Eureka∙ConfigServer 완전 제거 |
서비스 간 통신 | 평문 → mTLS 암호화 |
관측성 | 메트릭∙로그∙트레이스 통합 체계 |
운영 성과
항목 | 변화 |
Docker Build 시간 | 레이어 캐싱을 통한 빌드 타임 단축 1분 3초 → 3.2초 |
배포 재현성 | 선언적 GitOps 기반으로 확보 |
인프라 재현성 | 수동 설정 반복 → Terraform 기반 재구성 |
시크릿 관리 | 환경변수 직접 관리 → SSM + External Secrets |
비용 절감 | 확장되는 노드들에 대해 Spot Instance를 사용 |
7. 프로젝트 이후 보완 Lab
COME2US에서 일정상 완성하지 못했던 Canary 배포와 Circuit Breaker 시나리오를 프로젝트 종료 후 k3d 로컬 환경에서 별도로 구현·검증했습니다.
Istio 1.29.0과 httpbin을 사용해 DestinationRule 기반 Circuit Breaker, stable/canary subset, VirtualService 기반 weight 라우팅을 구성했고, 수동 Canary 전환과 Envoy sidecar의 비정상 엔드포인트 차단 동작을 확인했습니다.
이를 통해 COME2US에서 설계로 남아 있던 트래픽 관리 시나리오를 실제 동작 수준까지 보완했습니다.